Описание программы
Программа KeyClusterer предназначена для работы с семантическими ядрами больших и малых размеров и автоматической кластеризации поисковых запросов.
Основные возможности
- Автоматическая кластеризация семантических ядер любых объемов методами Hard и Soft.
- Импорт данных из Key Collector для группировки фраз без использования XML-лимитов.
- Проверка позиций по запросам и определение релевантных посадочных страниц.
- Двухпанельный интерфейс для удобной группировки запросов в ручном режиме.
- Использование списка стоп-слов для манипуляции ключевыми запросами.
- Фильтрация данных по ключевым запросам с подсветкой найденных слов.
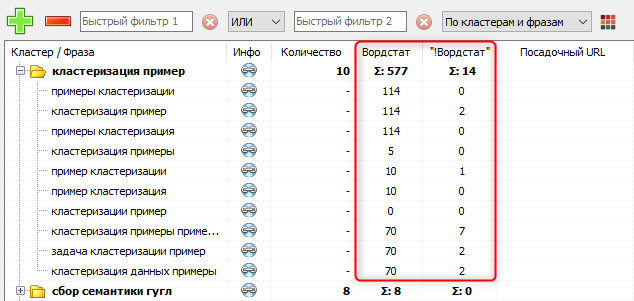
- Сбор «грязной» и «точной» частотностей запросов по Яндекс Вордстат.
- Отображение ТОП сайтов поисковой выдачи по группам запросов.
- Отмена последних действий при работе с семантическим ядром.
- Проверка Геозависимости и Коммерциализации запросов.
- Экспорт запросов в Excel и CSV формат.
Преимущества
- Высокая скорость кластеризации.
- Быстрое переключение между проектами.
- Низкие требования к ресурсам компьютера, малый расход оперативной памяти.
Меню
Запуск программы и кластеризация
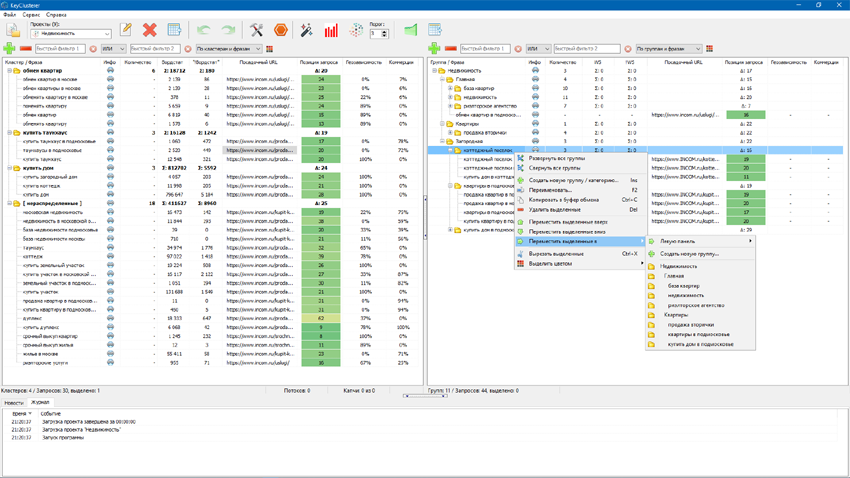
После запуска программы KeyClusterer пользователю предоставляется область для работы с ключевыми запросами, состоящая из двух панелей, а также набор дополнительных настроек и инструментов для сбора семантики и действий с семантическим ядром.
Для добавления нового проекта необходимо нажать копку «Добавить проект» через меню программы или тулбар, ввести его название, выбрать регион, выбрать число сайтов в поисковой выдаче по которым будет происходить кластеризация и указать домен (опционально).
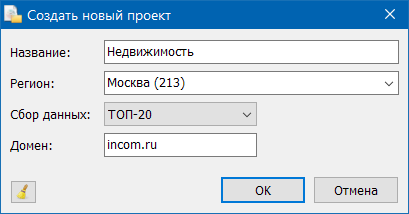
Пункт «Сбор данных» – это число документов, которое будет получено из поисковой системы Яндекс или Google. В последующем по ним будет производиться группировка запросов. Мы рекомендуем брать первые 10 документов выдачи.
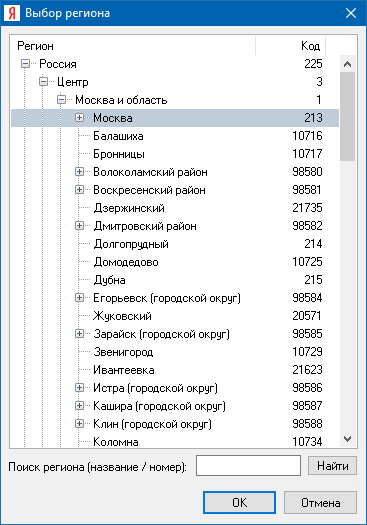
При выборе региона Яндекса имеется возможность быстрого поиска региона по его названию или числовому идентификатору.
В отличие от Яндекса, для которого указывается лишь регион выдачи, для Google необходимо указывать более подробное местоположение:
- Домен (google.com, google.ru, google.com.ua...).
- Язык (Russian, English, Ukrainian...).
- Страна (Russian Federation, United States, Ukraine...).
- Место («Moscow,Russia», «New York,United States», «Kyiv city,Ukraine»...).
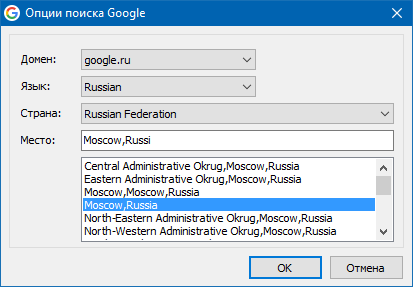
Например, при указании в поисковой системе Google домена «google.com.ua», поисковик будет производить поиск только в украинском сегменте интернета, а при дополнительном указании региона «Kyiv city,Ukraine», будет получать данные с учетом указанного местоположения.
После создания проекта становится возможным добавление поисковых запросов для кластеризации. Добавление запросов возможно 3-мя способами:
- Добавление запросов из буфера обмена.
- Добавление запросов из текстового файла.
- Импорт данных из CSV.
- Импорт данных из Key Collector 4 (*.kc4).
При добавлении запросов через буфер обмена или из текстового файла, все они сначала отобразятся не сгруппированными, так как по ним еще не собраны необходимые данные.
После нажатия кнопки «Собрать данные» происходит сбор данных из ТОП поисковой выдачи Яндекс, после чего становится доступной функция автоматической кластеризации запросов (кнопка «Кластеризовать»).
Импорт данных из CSV / Key Collector
Смысл импорта заключается в загрузке ранее собранных данных по частоте и результатам поисковой выдачи. Это может быть обычный CSV-файл, либо данные, импортированные из программы Key Collector.
После указания имени импортируемого файла программа KeyClusterer сама автоматически попытается определить наличие нужных полей в CSV-файле для импорта данных. При необходимости, можно вручную указать поля из которых будут взяты данные для импорта. Все остальные несопоставленные поля в импортируемом файле будут проигнорированы.
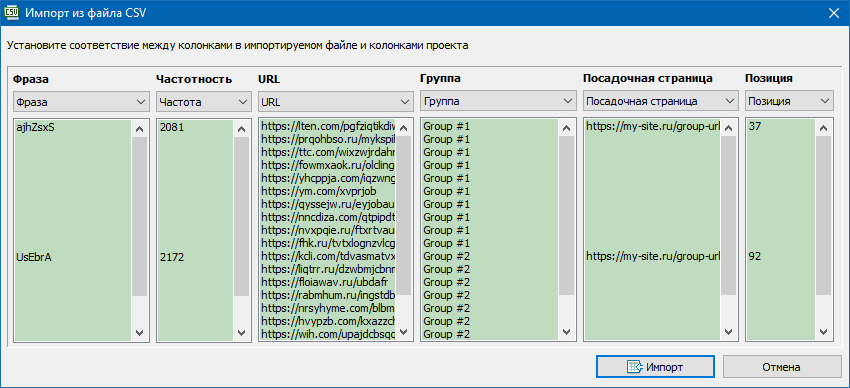
После импорта, запросы будут сгруппированы исходя из текущего содержимого импортируемого файла, после чего их можно будет кластеризовать непосредственно через программу.
Формат CSV-файла импорта:
- Запрос
- Частотность запроса
- URL сайтов выдачи по ТОП
- Группа
- Посадочная страница
- Позиция запроса в ТОП
Получение поисковой выдачи в Key Collector
|

После того, как были собраны все необходимые данные по ключевым фразам, можно переходить к процессу кластеризации (кнопка «Кластеризовать»).

При необходимости, в этом же окне можно скорректировать силу группировки и метод кластеризации и перекластеризовать запросы заново.
После окончания процесса группировки, в левой панели программы KeyClusterer список фраз заменится папками со сгруппированными в них запросами. Названия папок определяются автоматически по одной из ключевых фраз группы (обычно это самая частотная фраза). Запросы, которые не смогли автоматически сгруппироваться с другими фразами по текущим настройкам кластеризации будут находиться в папке под названием «[ несгруппировано ]».
Настройки KeyClusterer
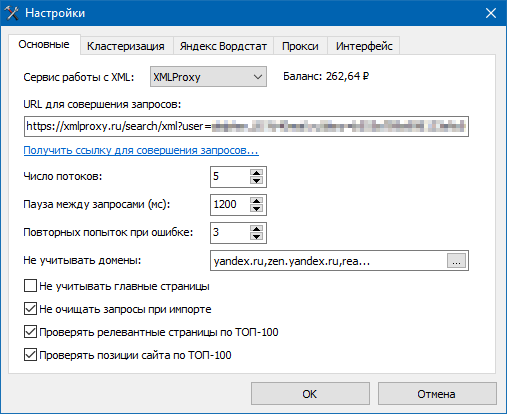
Для автоматической кластеризации семантического ядра необходимо выбрать сервис сбора поисковой выдачи в ПС Яндекс для последующей автоматической кластеризации запросов. На данный момент доступно шесть сервисов сбора данных в Яндекс и Google:
- Яндекс XML (Яндекс)
- Majento (Яндекс)
- SERPRiver (Яндекс)
- XMLProxy (Яндекс)
- XMLRiver (Яндекс / Google)
- XMLStock (Яндекс / Google)
На основе полученных, при помощи этих систем, данных, будет производиться автоматическая группировка запросов.
Отличие между Яндекс XML и Majento На данный момент Яндекс позволяет получать владельцам сайтов определенный лимит запросов в сутки через сервис Яндекс XML. Однако этот лимит ограничен (ограничение в использовании по времени суток, а также по общему числу запросов в день) и зависит от различных показателей сайта, в основе которых лежит популярность ресурса (чем крупнее и известнее сайт, тем больше лимитов ему предоставляется). Дополнительно, Яндекс предоставил возможность делегирования лимитов другим пользователям (передача прав на использование), что дало толчок к созданию инструмента аренды XML лимитов. Таким образом, использование XML лимитов Яндекса в системе Majento позволяет использовать их без каких-либо ограничений. Преимущества работы с Majento
|
Далее, нужно указать дополнительные настройки сбора данных в поисковой системе Яндекс.
Разберем по пунктам.
Данная настройка используется для предотвращения излишне частых обращений к сервисам сбора данных выдачи, иначе при особо частых запросах к системам данные по некоторым запросам могут быть собраны некорректно либо не собраны вовсе. Для нормально работы мы рекомендуем установить паузу в 1500 миллисекунд. Если в логе будет много сообщений о пропущенных запросах, можно увеличить это значение до момента, когда подобные сообщения перестанут появляться в логе программы.
Число потоков сканирования. Чем больше потоков, тем быстрее происходит сбор данных для последующей кластеризации. Однако, при большом количестве потоков могут возникать ситуации, когда данные выдачи по тому или иному запросу могут быть не получены, поэтому мы рекомендуем использовать оптимальное значение числа потоков в диапазоне от 3 до 5 и анализировать лог программы.
Число повторных запросов при неудачной попытке получения данных о поисковом запросе. Если все попытки будут исчерпаны, в программе есть возможность запуска перепроверки поисковых запросов, получение данных по которым ранее вернуло ошибку.
Блок «Не учитывать» предназначен для настройки исключений определенных сайтов при кластеризации:
- Сервисы Яндекса (список сервисов встроен в программу и не доступен для редактирования).
- Произвольные ресурсы (редактируемый список в виде указания доменов игнорируемых сайтов).
- Главные страницы (если выдача состоит только из Главных страниц, то кластеризация в автоматическом режиме будет безрезультатна).
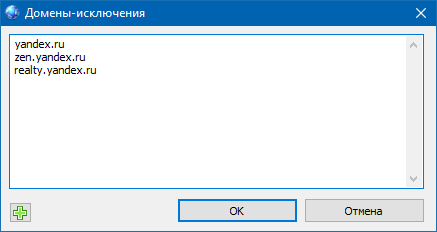
Проверка позиций и релевантных страниц
- Если пункт «Проверять релевантные страницы» активен, то при сборе данных о поисковых запросах одновременно будут проверяться релевантные страницы по домену, указанному в настройках проекта. Если домен в свойствах проекта не указан, то данные о релевантных страницах не отобразятся.
- Пункт проверки позиций сайта работает аналогично проверке релевантных страниц.
Проверка позиций и релевантных страниц проводится по ТОП-100 выдачи Яндекса.
Данные два действия можно проверять и отдельно, используя контекстное меню левой панели программы.
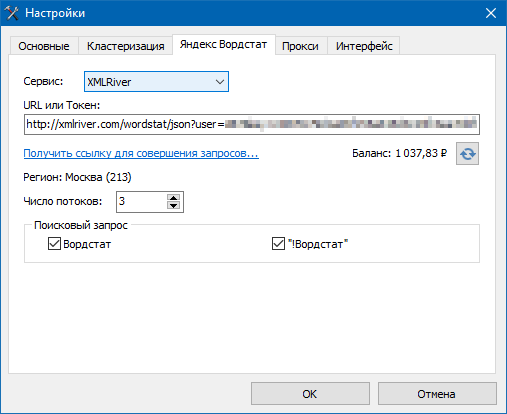
При помощи сбора «грязной» и «точной» частотностей запроса по сервису Яндекс Вордстат можно собирать статистику поисковых запросов Яндекса используя API сервисов Word Keeper и XMLRiver. Цена за 1000 запросов у обоих сервисов равна 20 рублей (при этом у Word Keeper минимальное пополнение баланса 399 рублей, у XMLRiver – от одного рубля).
Настройка парсинга Яндекс Вордстат: после регистрации в одном из двух сервисов, необходимо скопировать в личном кабинете API-ключ (для XMLRiver) или токен (для Word Keeper) и затем вставить их в настройки программы.
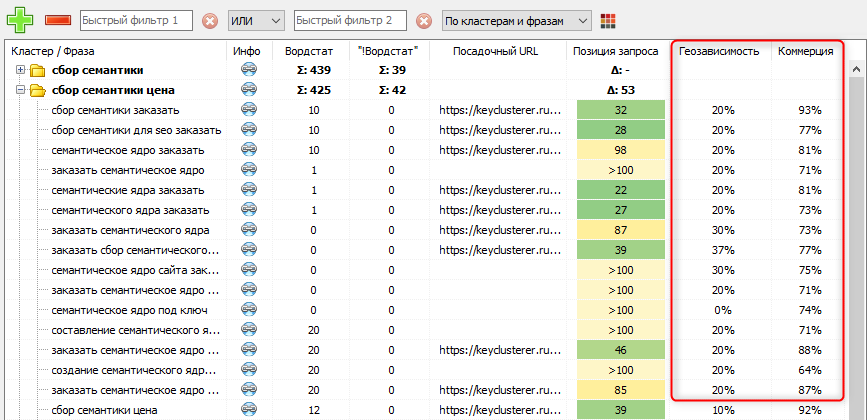
Понимание о геозависимости или геонезависмости поискового запроса часто бывает полезно при подборе семантического ядра.
- Например, если выдача по одному и тому же поисковому запросу отличается для пользователей из разных регионов России, то такой запрос считается геозависисимым. Иначе, если выдача по запросу совпадает для пользователей из всех регионов России – то запрос является геонезависимым.
- KeyClusterer проверяет геозависимось запроса путем сравнения поисковой выдачи в двух разных регионах России. При полном совпадении поисковой выдачи запрос является геонезависимым, иначе, если выдача отличается, то запрос считается геозависимым.
- Также для геозависимых запросов определяется степень этой зависимости относительно числа «пересекающихся» сайтов по ТОП, и выражается в виде коэффициента.
- Глубина проверки позиций: 20.
- Расход XML-лимитов на один поисковый запрос: 2 шт.
Понятие «коммерциализация» определяет долю коммерческих результатов в результатах выдачи Яндекса по ключевому запросу.
- Инструмент анализирует поисковую выдачу по запросу и проверяет наличие коммерческих характеристик в свойствах сайтов и их заголовков на предмет вхождения в них таких слов, как «цена», «заказать», «купить» и т.п. После обработки полученных данных коммерческость запроса отображается в процентном выражении от 0 до 100%.
- Градации показателей:
- 0-30% – информационный запрос
- 30-60% – смешанный
- 60-100% – коммерческий
- Глубина проверки позиций: 20.
- Расход XML-лимитов на один поисковый запрос: 2 шт.
Вкладка «Кластеризация» предназначена для указания способа группировки поисковых запросов одним из 2-х методов: Hard или Soft.
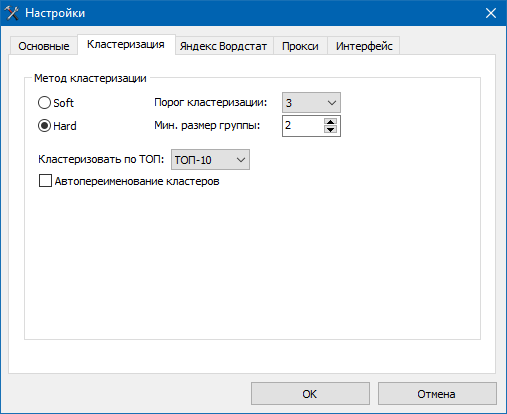
Оба варианта кластеризации в числовом виде отображают так называемый параметр «Порог кластеризации», нормируемый по шкале от 1 до 10. Параметр «Порог кластеризации» отвечает за то, насколько должны быть похожи запросы по десятибалльной шкале, чтобы попасть в одну группу.
- То есть, если установить порог кластеризации = 1, то запросы для попадания в одну группу должны быть минимально похожими, однако, таким образом создастся мало групп, в каждой из который будет много запросов.
- Если, напротив, установить порог равным 10, то запросы должны быть максимально похожими, чтобы попасть в одну группу, таким образом, создастся много групп, но запросы будут них максимально похожими.
Мы рекомендуем кластеризовать методом Hard, так как он считается наиболее качественным.
- Метод Hard: запросы объединяются в группу, только если есть общий для всех запросов набор URL, который показывается по ВСЕМ этим запросам в ТОП-10. Общепринятая сила группировки для метода Hard = 3.
- Оба варианта Hard-кластеризации, представленные на скриншоте, дают возможность получать заданное качество группировок относительно количества итоговых групп запросов и общего времени, затраченного на кластеризацию. Все это варьируется через дополнительные настройки.
- Метод Soft: выбирается «центральный» запрос, с которым сравниваются остальные запросы по количеству общих URL в ТОП-10 Яндекса. Если количество общих URL-ов превышает порог – запрос добавляется в группу. Общепринятая сила группировки для метода Soft = 4.
Примечание: перекластеризация с другими настройками не влечет за собой новый сбор данных. То есть, один раз собрав ТОП, потом можно настраивать кластеризатор «под себя», анализируя полученные результаты группировок.
Число документов, отбираемое для группировки запросов по ТОП 10, 20, 30, 50. Мы рекомендуем выбрать вариант «ТОП-10», так как данный список результатов поисковой выдачи зачастую состоит из наиболее качественных сайтов.
Переименовывание кластеров
Переименовывание кластеров удобно для визуального отличия кластеров друг от друга, так как при такам подходе будут использоваться наиболее короткие названия из группы запросов кластера (это связано с тем, что название группы берется по самому частотному запросу в кластере, а такие запросы обычно являются наиболее короткими). Если же ни у одного запроса в группе не указана частота Вордстат, то ее название берется по первому запросу в группе.
При этом, название каждой группы все также остается доступным для ручного редактирования.
Работа с группировками запросов
После того, как запросы были кластеризованы (результат кластеризации будет виден все в той же левой панели программы), вы можете их экспортировать в файлы Excel и CSV формата.
Однако, как известно, какой бы качественной не была автоматическая группировка запросов, она все также будет нуждаться в «ручной» доработке, так как на данный момент, лучше человека понимать тонкости продвижения отдельных запросов и групп искусственный алгоритм еще не научился.
Дополнительно, в ручном режиме есть возможность посредством правой панели создавать произвольные группы любой вложенности и, таким образом, перенося в них кластеры из левой панели, создавать структуру вашего сайта прямо в программе с последующей возможностью экспорта итоговой структуры в Excel и сохранением форматирования относительно вложенности групп запросов.
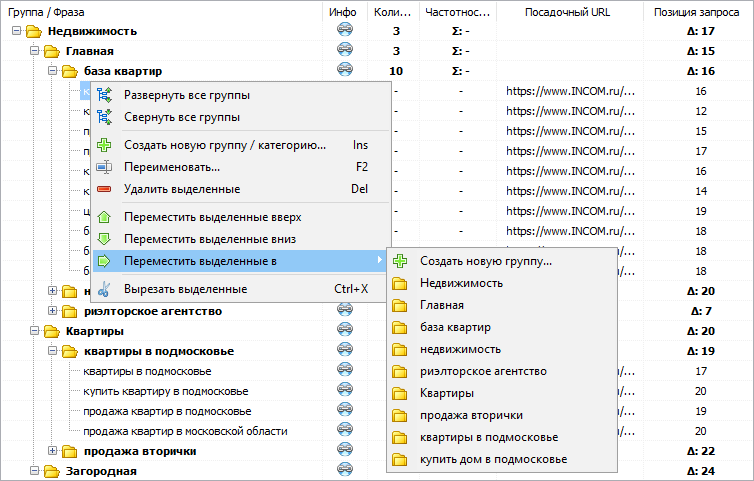
Помимо переноса фраз, есть возможность удаления запросов, создание и переименование кластеров и групп.
Все эти манипуляции доступны через контекстное меню панелей группировки фраз.
При помощи цветовых маркеров можно выделять цветом строки с интересующими запросами, а затем производить по ним фильтрацию аналогично тому, как это реализовано в Key Collector и KeyAssort.
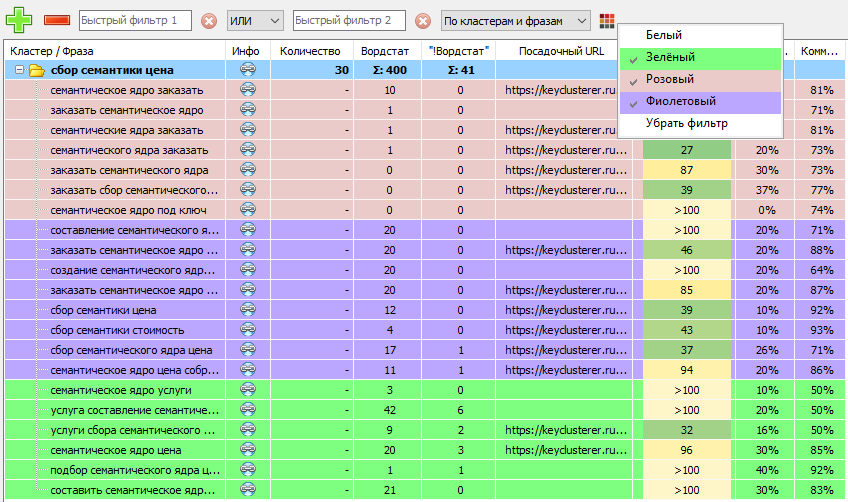
При этом в фильтр «По цвету» будет отображать цвета, которые использовались при выделении хотя бы одного запроса.
При помощи данного функционала можно выделять ключевые слова в левой или правой панели по определенным правилам и проводить над ними дальнейшие действия: удаление, перемещение и т.п.
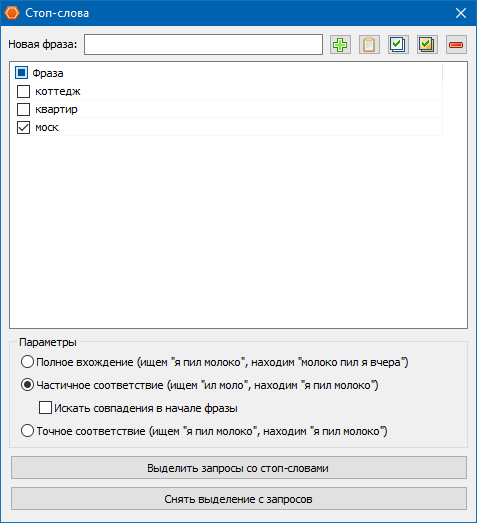
Параметры действий при поиске запросов:
- Полное вхождение (ищем «я пил молоко», находим «молоко я пил вчера»).
- Частичное соответствие (ищем «ил моло», находим «я пил молоко»).
- Точное соответствие (ищем «я пил молоко», находим «я пил молоко»).
Это бывает удобно, например, для удаления ключевых слов из семантического ядра по списку стоп-слов, либо для поиска ключевых фраз по вхождению определенного слова, которые затем можно переместить в ту или иную группу.
Сортировка запросов и фильтрация
Отсортировать запросы можно при помощи нажатия на заголовки соответствующих столбцов. При нажатии на колонку «Частотность», запросы будут отсортированы по частоте запроса внутри каждой группы. Аналогично, при нажатии на заголовок колонки с запросами – они будут отсортированы по алфавиту. Группы запросов сортируются через пункт в контекстном меню.
Фильтрация данных позволяет фильтровать запросы по фразам, группам и частоте (если указана).
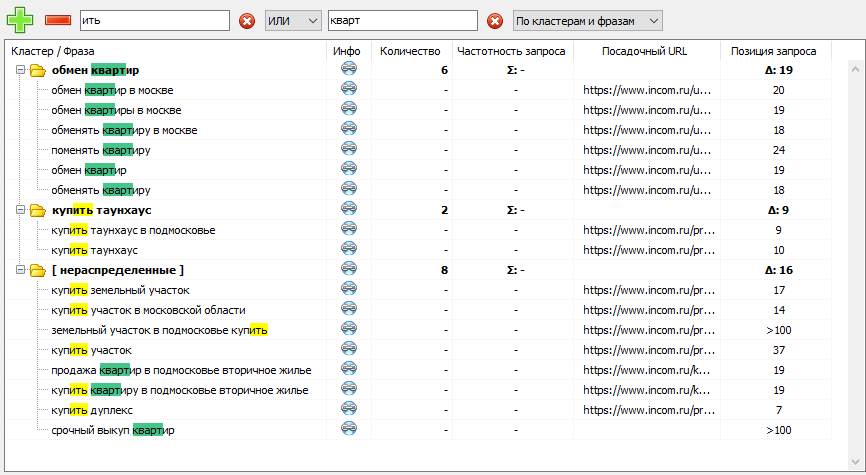
При фильтрации данных, найденные части слова из первого фильтра выделяются желтым цветом, а из второго – зеленым.
Дополнительно
Данный список поможет выявить наиболее популярные сайты в вашей тематике (сайты в списке отсортированы по числу запросов, входящих в ТОП-10 по каждому сайту).
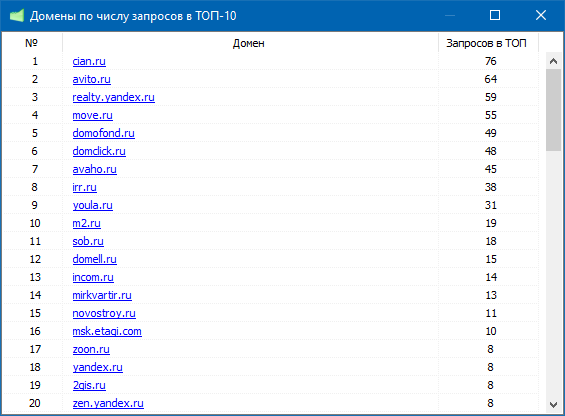
Данные для анализа берутся берутся из поисковой выдачи, собранной по каждому запросу, соответственно, для отображения статистики, данные SERP должны изначально присутствовать (должны быть собраны тем или иным способом).
При желании есть возможность выгрузки данных в Excel (CSV-формат).
Помимо добавления прокси-серверов есть возможность проверки списка прокси на работоспособность. В остальном, работа через прокси ничем не отличатся от работы в других программах.
Данная функция позволяет отменить последние действия, произведенные при ручной кластеризации запросов.

Будь это перемещение запросов или кластеров, создание групп, переименование или удаление запросов – все это теперь можно отменить и вернуться на тот или иной момент ручной кластеризации без необходимости начинать все сначала.
Число «откатов» истории действий зависит от объема оперативной памяти вашего ПК. Чем памяти больше, тем больше вариантов возврата к предыдущим действиям по выбранному проекту.
В программе реализовано автоматическое сохранение данных.
Вы можете быть уверены, что каждый раз при добавлении или удалении проекта, после кластеризации запросов и ручной манипуляции с запросами все данные сохранятся в программе автоматически.
Удаление проекта и сжатие данных
Пункт меню «Сжать базу данных» предназначен для выполнения операции очистки и упаковки имеющихся баз данных (аналог дефрагментации данных на персональных компьютерах).
Данная процедура эффективна в случае, когда например, из программы был удален крупный проект, содержащий большое количество записей. В целом рекомендуется проводить периодическое сжатие данных для избавления от избыточных данных и уменьшения объема базы.
Экспорт
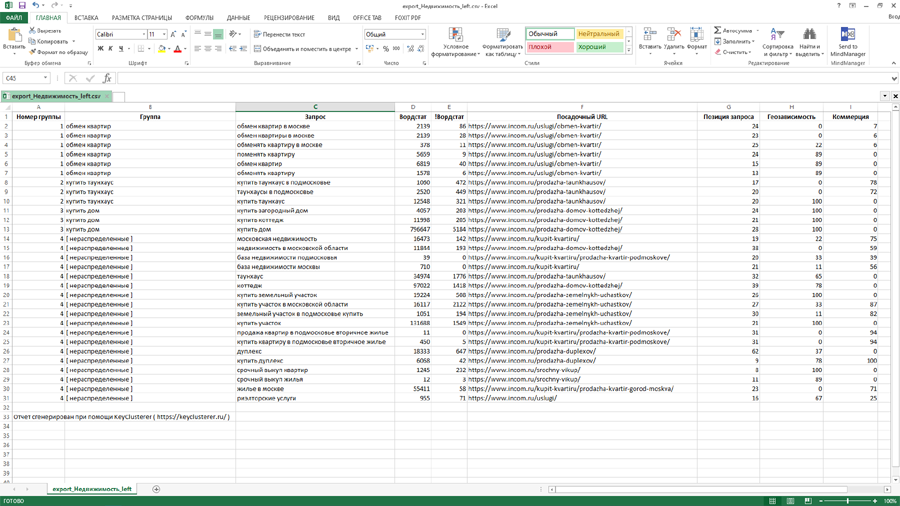
Есть возможность экспорта данных в формате CSV и Excel.
- При экспорте данных в файл формата CSV экспортируются только данные из правой панели.
- При экспорте в Excel, помимо данных из правой панели, появляется вторая вкладка, которая отображает структуру сайта с учетом вложенности.